CA Wily Introscope
We wound up using Wily for most of our monitoring needs in the WebLogic tier. On the whole it did the job that we expected of it very well.
Our main thoughts on our Wily experience are...
- The fact that Wily's monitoring is 'always on' was a big advantage, as well as the ability to get historical results in graphical or CSV format.
- We were not able to use any custom probes because Wily was installed and configured by the customer's infrastructure team and getting custom probes created, tested and deployed was just going to need too many phone calls and email round trips.
- Initially there were quite a lot of navigation steps and other clicking around needed to capture all of the metrics that we needed into graphs or CSV form. We largely overcame this by creating some metric groupings and custom dashboards to bring all of the necessary data together into one place.
- For some reason, the JMX data from the Camel route MBeans was not captured by Wily during our tests (although the processor MBeans worked fine and the route MBeans worked fine before we started the tests).
- Wily didn't recognise our Apache CXFServlet as a 'Frontend' (but it knew it was a Servlet) nor did it recognise outbound web service and TIBCO calls as 'Backends', so some of the more advanced features (e.g. transaction tracing) were not usable.
- Wily often picks a non-intuitive sampling interval for graphs (e.g. 6 minutes) but it was quite easy to override this and use something more sensible.
- Data captured from JMX MBeans needed some further analysis afterwards to calculate the throughput and average response times during the test period. It may have been possible to use Wily calculators to automate this, but we didn't have time to get that far
JRockit Mission Control
We had a couple of issues with JRMC right from the start. These were probably not faults with the tool, but they severely limited its usefulness
- Our customer had an older version of JRockit than that supported by the latest version of JRMC, so we needed to downgrade to JRMC 3.1.2 before most of the JRMC features would work.
- We never managed to get any kind of recording capability to work. JRMC 3.1.2 has JRA recording, but whenever we tried this it would cause the WebLogic managed server to go into an 'UNKNOWN' state and stop working. I've tested JRA recording on my local setup and it works fine, so this issue seems to be specific to our customer's managed WebLogic setup. It may have been fixable but we didn't get this far.
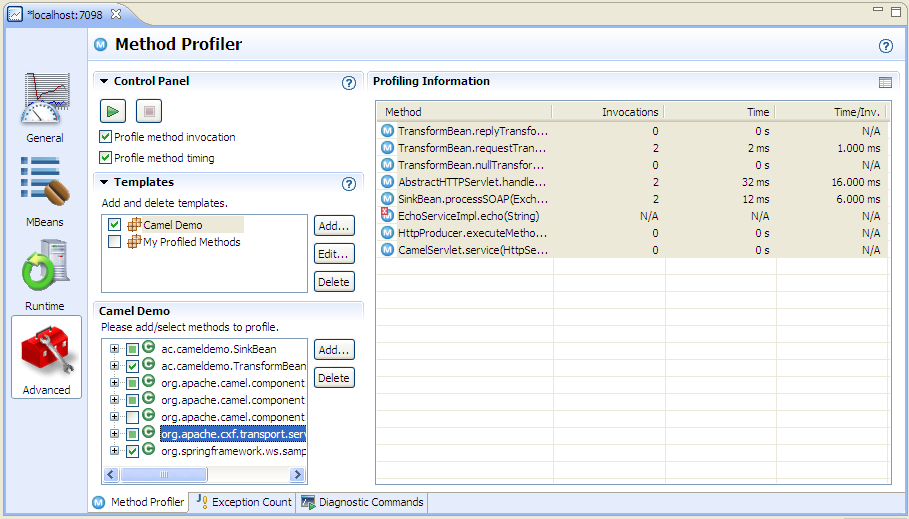
We were able to use JRMC to fill this gap by using JRMC method profiling to trap the web service and TIBCO callouts. This wasn't a perfect setup because it could only give us an average response time for the whole test. It also had a few other issues:-
- Someone needs to remember to start the method profiler before the test and save the results afterwards.
- It isn't easy to share JRMC method profiling configurations (or any other JRMC configuration) with other team members, so each person had to set the probes up manually.
- Only one person can use method profiling on a managed server at a time. If someone accidentally starts profiling while another session is in progress the first session is terminated.
- We had one occasion on which the Windows machine running JRMC automatically rebooted itself part way through a 24 hour test run so we lost all of the JRMC data prior to the reboot.
Summary
On the whole, our experience has reinforced my original conclusions that JRMC is a good tool for single developers or testers to quickly get a handle on how their Java code is performing but that Wily is much stronger in a team environment or for production monitoring.
In the end it wasn't an 'either/or' decision for us - we needed to use both tools to capture the data that we needed.