When designing clustered WebLogic deployments that use JMS it is usual to introduce load balancing into the JMS infrastructure so that incoming transaction arriving via JMS get distributed evenly across the servers in the cluster. The way that this is done in WebLogic is by creating a distributed destination with an individual physical queue in each member of the cluster. This allows the application components (e.g. EJB Message Driven Beans) to be configured with a single JNDI name so that the same application component can be deployed to every node in the cluster and will continue to work even if a cluster member goes down. Load balancing is enabled via the connection factory settings by specifying that the JMS connection factory should have load balancing enabled and (usually) server affinity disabled. This is usually a good thing.
For outbound messages (e.g. response messages from the same transactions) it is also normal to set up a distributed destination, again so that the application can be written with a single configured JNDI name which will work everywhere in the cluster. It is also possible to use a load balanced connection factory for the outbound messages. I can see no real advantages to using load balancing in this context. Gut feel and colleagues told me that it was a bad idea but until recently I could not point to any proven problems with this setup.
I have now seen an example of a real problem which seems to be happen when outbound load balancing is used…
First a little scene setting. One of the other advantages of clustering is that when we find ourselves facing one of those situations that should not happen and need to restart the application we can do so without making the whole system unavailable by doing a ‘rolling bounce’ in which the cluster members are bounced in turn so that there is never a time when none of them are available.
Recently we received reports of that one of our client systems was occasionally timing out waiting for JMS responses from us. This seemed to be happening in bursts at the same time as we were doing a rolling bounce to resolve an unrelated issue. Checking our database showed that we had processed the transaction and recorded a response message. Checking the logs, however, showed that there had been a problem…
[16/02/11 04:01:48:048 GMT] ABC_COMPONENT ERROR Exception Logger: Caught exception during processing void com.xyz.abc.common.servicelayer.SimpleJmsSender.sendMessage(String, Map)
org.springframework.jms.IllegalStateException: [JMSClientExceptions:055076]The session is closed; nested exception is weblogic.jms.common.AlreadyClosedException: [JMSClientExceptions:055076]The session is closed
at org.springframework.jms.support.JmsUtils.convertJmsAccessException(JmsUtils.java:252)
at org.springframework.jms.support.JmsAccessor.convertJmsAccessException(JmsAccessor.java:172)
Collecting up all of the logs from the cluster members showed that these exceptions always happened when one of the other managed servers in the cluster was being bounced. I concluded from this that the outbound messages were being round-robin load balanced across all of the managed servers and that when one server was bounced it caused errors to the applications running on the remaining servers.
Now I think that WebLogic JMS should handle this rather better. I also know that the application’s error handling needs to be improved so that it doesn’t commit the database changes if the JMS response message transmission fails. Nevertheless it does highlight a scenario in which outbound load balancing introduces the possibility of a problem which would not be there if the outbound messages were sent without load balancing.
Conclusion: when using a distributed JMS destination to send outbound messages from a cluster you should use a connection factory with load balancing disabled and server affinity enabled.
Before closing it’s worth observing that outbound load balancing is something that I’ve seen configured on several WebLogic projects and thinking about why this is so…
Most of the projects that I’ve seen have begun life in a non-clustered setup. In such a setup it is usual to use a single JMS connection factory for both inbound and outbound messages. Unless there is some special tuning required then there is no real problem with such a setup. When clustering is introduced the team reads the manual, learns about distributed JMS destinations and creates them. They introduce inbound load balancing by reconfiguring their existing connection factory but stick with the single connection factory setup and overlook the fact that they have also implicitly introduced outbound load balancing.
Showing posts with label Availability. Show all posts
Showing posts with label Availability. Show all posts
Monday, 28 February 2011
Friday, 13 August 2010
An End in Sight to Upgrade Downtime?
One of the recurring concerns that our customers raise with us is the amount of downtime required when we make a change to the application.
We have spent time and money putting a bunch of high availability technologies in place so it always seems disappointing to have to ask for downtime to do something as simple as an application code change. Somehow this fairly frequent activity has not caught the attention of the folks who think up clever new ways to improve database availability... until now.
In our case the application is a Telecoms inventory solution based on the Amdocs Cramer product using J2EE (WebLogic or Oracle App Server) and an Oracle database. The product is very 'database heavy' in that a large proportion of its code resides in the database as Oracle stored procedures or database resident Java code. The complexity of the dependencies inside the product means that any changes typically require an outage of several hours while the database code is replaced and recompiled.
We have looked at various ways to solve this problem. The main option being to run multiple instances of the application and replicate data changes between them somehow. When upgrade time arrives, one instance can be used to apply the code changes while the other stays online running transactions and the data changes are replicated across before the instance with the updated code takes over as the live instance. We've looked at Oracle streams, Data Guard SQL Apply and GoldenGate as possible solutions. All of them seemed to offer the possibility of doing the job but somehow the complexity and cost always meant that the idea was never followed through to implementation.
There is now another way to achieve the same result - without the need for a separate instance of the application. Oracle 11g release 2 has introduced a feature called 'Edition-Based Redefinition'. The new feature allows multiple versions of the same procedure to exist in the database so that clients can carry on using the old version while the new one is being built. The new versions can also be kept
separate during testing and if necessary even run in parallel for longer periods of time.
Edition-Based Redefinition is probably still some way in the future for us at the moment - I think it will need changes by our product vendor, not least that they need to support Oracle 11g.
Some links containing more detail:-
A 2 part YouTube video with Bryn Llewellyn
Part 1
Part 2
Tom Kyte's very thorough explanation of Edition-Based Redefinition
Part 1
Part 2
Part 3
Bryn Llewellyn's White Paper
The Manual
We have spent time and money putting a bunch of high availability technologies in place so it always seems disappointing to have to ask for downtime to do something as simple as an application code change. Somehow this fairly frequent activity has not caught the attention of the folks who think up clever new ways to improve database availability... until now.
In our case the application is a Telecoms inventory solution based on the Amdocs Cramer product using J2EE (WebLogic or Oracle App Server) and an Oracle database. The product is very 'database heavy' in that a large proportion of its code resides in the database as Oracle stored procedures or database resident Java code. The complexity of the dependencies inside the product means that any changes typically require an outage of several hours while the database code is replaced and recompiled.
We have looked at various ways to solve this problem. The main option being to run multiple instances of the application and replicate data changes between them somehow. When upgrade time arrives, one instance can be used to apply the code changes while the other stays online running transactions and the data changes are replicated across before the instance with the updated code takes over as the live instance. We've looked at Oracle streams, Data Guard SQL Apply and GoldenGate as possible solutions. All of them seemed to offer the possibility of doing the job but somehow the complexity and cost always meant that the idea was never followed through to implementation.
There is now another way to achieve the same result - without the need for a separate instance of the application. Oracle 11g release 2 has introduced a feature called 'Edition-Based Redefinition'. The new feature allows multiple versions of the same procedure to exist in the database so that clients can carry on using the old version while the new one is being built. The new versions can also be kept
separate during testing and if necessary even run in parallel for longer periods of time.
Edition-Based Redefinition is probably still some way in the future for us at the moment - I think it will need changes by our product vendor, not least that they need to support Oracle 11g.
Some links containing more detail:-
A 2 part YouTube video with Bryn Llewellyn
Part 1
Part 2
Tom Kyte's very thorough explanation of Edition-Based Redefinition
Part 1
Part 2
Part 3
Bryn Llewellyn's White Paper
The Manual
Friday, 30 April 2010
Memory Leak Case Studies Part 3
The third and final installment (probably) in the series on memory leak case studies describing real memory leaks and similar Java heap stress conditions that I’ve seen myself and how they were tracked down and fixed.
This particular issue took a long time to resolve because it wasn't in code that we controlled and tracking down information about the problem proved very difficult.
weblogic.jms.dd.DDMember
After clustering our WebLogic 9.2 servers we found that the managed servers would run into major heap stress and sometimes go offline on some of our test environments. Unfortunately the problem was not easily reproducible and didn't seem to happen on environments that we could easily mess with.
A heap histogram from jmap looked like...
255076744 2969890 char[]
71728608 2988692 java.lang.String
34196104 287745 * ConstMethodKlass
30874880 385936 weblogic.jms.dd.DDMember
20721808 287745 * MethodKlass
18528600 772025 weblogic.jms.common.JMSID
18527736 771989 weblogic.messaging.dispatcher.DispatcherId
15454080 386352 weblogic.cluster.BasicServiceOffer
14538712 24883 * ConstantPoolKlass
12604000 259169 * SymbolKlass
10601304 24883 * InstanceKlassKlass
9763528 29806 byte[]
9262056 385919 weblogic.jms.dd.DDMemberStatusSharer
7797008 18852 * ConstantPoolCacheKlass
6628720 118370 org.codehaus.groovy.runtime.metaclass.MetaMethodIndex$Entry
6175856 385991 weblogic.jms.common.JMSServerId
We also got some heap dumps, but it was pretty obvious from the outset that the memory leak related to WebLogic internal classes. We checked and ruled out the obvious things that were under our control (e.g. too many messages building up in JMS queues). We also googled for the problem and searched Oracle Metalink but didn't turn up any useful advice. The only option left was to raise a case with Oracle, which is what we did.
Oracle responded to the case with the advice to increase the heap size to 2Gb on all servers. We did this and our test environments became more stable. the problem did not recur in test so eventually the clustering changes made it into production.
I'm sure that you can guess where this story is going ...
After clustering went live we found that the managed servers would stay up for roughly 24 hours before running into problems and needing to be restarted. The initial symptoms that were noticed were BEA-000115 messages (which say that a multicast packet was lost) and BEA-000511 messages (which say unsolicited reply), along with high CPU utilisation.
Naturally a new Oracle case was opened. Initially it was thought that the problem was being caused by a poor choice of multicast addresses. Another week went by while the system was reconfigured with what seemed to be better multicast addresses, but still the problem remained.
I did some analysis of the logs using Splunk (a great tool BTW, but that's another story) and found that the messages seemed to appear in bursts starting an hour or two before the CPU utilisation became really high. Here is a Splunk graph showing the occurrences of one of the message types.

I'd also asked for jstat data which confirmed that the servers were filling up their heaps. I also found that the WebLogic logs contained some BEA-310002 messages that shed some light on the behaviour of the problem over a longer period. I used splunk to produce a graph from these:-

This graph seemed to indicate that the problem was related to the uptime of the servers rather than the amount of work they were doing (the behaviour was the same on a Sunday as on a working day). This prompted an idea for improving the stability of our system - avoid restarting all of the servers at the same time and then there would be a good chance that they wouldn't all fail at the same time. Unfortunately the change control procedures for the production system pretty much ruled this out, so we were stuck with restarting the servers each time they ran into trouble.
Finally Oracle support came back to us with the advice that this was a known bug in WebLogic for which a patch was available - 'BUG 8160383 - [CR368242]'. We applied this fix, tested it and put it into production and found that the problem was solved.
So I then wondered why we hadn't found the cause sooner. The Oracle support people said that the description of the patch said that it fixes "leaking objects weblogic.jms.dd.DDMember". I went back into Metalink and looked up the information relating to the bug and the patch and found that it contained mostly blank text and no mention at all of 'DDMember' which is probably why I couldn't find it. I wonder whether some of the information was perhaps lost in the transition from WebLogic's bug database into Metalink. Clearly the Oracle support people have another source of information available to them.
This particular issue took a long time to resolve because it wasn't in code that we controlled and tracking down information about the problem proved very difficult.
weblogic.jms.dd.DDMember
After clustering our WebLogic 9.2 servers we found that the managed servers would run into major heap stress and sometimes go offline on some of our test environments. Unfortunately the problem was not easily reproducible and didn't seem to happen on environments that we could easily mess with.
A heap histogram from jmap looked like...
255076744 2969890 char[]
71728608 2988692 java.lang.String
34196104 287745 * ConstMethodKlass
30874880 385936 weblogic.jms.dd.DDMember
20721808 287745 * MethodKlass
18528600 772025 weblogic.jms.common.JMSID
18527736 771989 weblogic.messaging.dispatcher.DispatcherId
15454080 386352 weblogic.cluster.BasicServiceOffer
14538712 24883 * ConstantPoolKlass
12604000 259169 * SymbolKlass
10601304 24883 * InstanceKlassKlass
9763528 29806 byte[]
9262056 385919 weblogic.jms.dd.DDMemberStatusSharer
7797008 18852 * ConstantPoolCacheKlass
6628720 118370 org.codehaus.groovy.runtime.metaclass.MetaMethodIndex$Entry
6175856 385991 weblogic.jms.common.JMSServerId
We also got some heap dumps, but it was pretty obvious from the outset that the memory leak related to WebLogic internal classes. We checked and ruled out the obvious things that were under our control (e.g. too many messages building up in JMS queues). We also googled for the problem and searched Oracle Metalink but didn't turn up any useful advice. The only option left was to raise a case with Oracle, which is what we did.
Oracle responded to the case with the advice to increase the heap size to 2Gb on all servers. We did this and our test environments became more stable. the problem did not recur in test so eventually the clustering changes made it into production.
I'm sure that you can guess where this story is going ...
After clustering went live we found that the managed servers would stay up for roughly 24 hours before running into problems and needing to be restarted. The initial symptoms that were noticed were BEA-000115 messages (which say that a multicast packet was lost) and BEA-000511 messages (which say unsolicited reply), along with high CPU utilisation.
Naturally a new Oracle case was opened. Initially it was thought that the problem was being caused by a poor choice of multicast addresses. Another week went by while the system was reconfigured with what seemed to be better multicast addresses, but still the problem remained.
I did some analysis of the logs using Splunk (a great tool BTW, but that's another story) and found that the messages seemed to appear in bursts starting an hour or two before the CPU utilisation became really high. Here is a Splunk graph showing the occurrences of one of the message types.

I'd also asked for jstat data which confirmed that the servers were filling up their heaps. I also found that the WebLogic logs contained some BEA-310002 messages that shed some light on the behaviour of the problem over a longer period. I used splunk to produce a graph from these:-
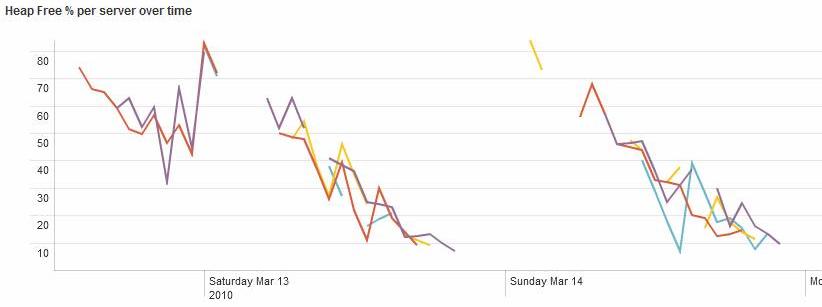
This graph seemed to indicate that the problem was related to the uptime of the servers rather than the amount of work they were doing (the behaviour was the same on a Sunday as on a working day). This prompted an idea for improving the stability of our system - avoid restarting all of the servers at the same time and then there would be a good chance that they wouldn't all fail at the same time. Unfortunately the change control procedures for the production system pretty much ruled this out, so we were stuck with restarting the servers each time they ran into trouble.
Finally Oracle support came back to us with the advice that this was a known bug in WebLogic for which a patch was available - 'BUG 8160383 - [CR368242]'. We applied this fix, tested it and put it into production and found that the problem was solved.
So I then wondered why we hadn't found the cause sooner. The Oracle support people said that the description of the patch said that it fixes "leaking objects weblogic.jms.dd.DDMember". I went back into Metalink and looked up the information relating to the bug and the patch and found that it contained mostly blank text and no mention at all of 'DDMember' which is probably why I couldn't find it. I wonder whether some of the information was perhaps lost in the transition from WebLogic's bug database into Metalink. Clearly the Oracle support people have another source of information available to them.
Wednesday, 8 August 2007
Challenges to Agile Development
It must be at least 12 years now since I attended the excellent two day course entitled 'Object Oriented Project Management'. Frankly it wasn't much about Object Oriented development and would perhaps have been better entitled 'Enlightened Project Management'. It introduced me to concepts like Boehm's spiral lifecycle, Tom Gilb's evolutionary delivery ideas and books of wisdom like 'The Mythical Man Month'. I had zero project management training prior to this but the wisdom on this course rather ruined me as an audience for the purveyors of more traditional project management techniques who have crossed my path since then.
As a result of this and my experience since then, I have become an advocate of agile development approaches (although it wasnt called 'agile' 12 years ago!). I have also encountered a lot of situations which pose challenges for agile practices. The main ones are:-
- Management of non-functional requirements - agile user stories tend to focus on obvious functional value. The fit of agile techniques to cross-cutting (but critical) concerns like security, performance or availability is less clear. Some have proposed non-functional user stories, but at the moment I think the jury is out.
- Outsourcing - having a customer/supplier relationship introduces barriers in communication, potentially conflicting motivation and reward systems and, in its usual form requires some form of big specification up front saying what is being paid for. All of these are driving us in the oppposite direction from the Agile Manifesto.
- Offshoring - an extension of outsourcing which introduces the additional challenges of physical distance, poor communications infrastructure, timezones, language and cultural differences - all of which conspire to hinder the free flow of communication which is the life blood of an agile project.
I dont claim to have all the answers to these issues. Some would say that a 'high ceremony' methodology is the only answer, but I'm not so sure. I do find myself facinng them on a regular basis, so at least I have some material for future posts!
Subscribe to:
Posts (Atom)

