I've posted a few times previously on the subject of Java heap analysis and related tools. My current tool of choioce is Eclipse MAT.
MAT provides a number of very useful features to allow users to quickly get an overview of what is happening in a heap dump and in many cases to identify the objects responsible for memory leaks. Sometimes, however, these are not enough. There are also situations where I need to ask the same question about multiple heap dumps without the need to go through multiple steps of navigation. This is where Object Query Language (OQL) can be very helpful.
For those who are unfamiliar with it, OQL is (as its name suggests) a language similar to SQL but intended to query collections of objects instead of rows in a database. The MAT project has chosen to implement OQL as a way to perform targeted queries on the objects in a heap dump.
You can find plenty of good documentation with MAT to help you to understand OQL syntax, but I found that there was rather a shortage of examples, so I thought it would be a good idea to post some here. These are all real queries that I have used to diagnose memory consumption issues (and leaks) on real projects. This does, of course, mean that the examples are biased towards the products I use most frequently - Oracle, WebLogic and some open source libraries.
After running these queries, it is often a good next step to ask MAT to calculate the retained size for each entry in the list. Then the results can be saved as a CSV file for further analysis using your favourite spreadsheet application.
JDBC object leaks are a regular cause for concern, so here are some queries to help...
SELECT toString(s.sqlObject.oracle_sql) FROM oracle.jdbc.driver.T4CCallableStatement s
SELECT toString(s.sqlObject.oracle_sql) FROM oracle.jdbc.driver.T4CPreparedStatement s
SELECT toString(poolname), lastSuccessfulConnectionUse,destroyed FROM weblogic.jdbc.common.internal.ConnectionEnv
The first two relate to JDBC statement leaks. Both are basically the same but they work on different types of statement. They may also be useful for result set leaks because the result set tends to hold a reference back to the statement. The third one provides a picture of JDBC connections in a WebLogic connection pool. In particular, it is useful to see which connections have not been used for a long time.
Another WebLogic JDBC Example...
SELECT stmtCache.list.size, toString(poolname) FROM weblogic.jdbc.common.internal.ConnectionEnv
This query also looks at WebLogic JDBC connections, but in this case it is examining the size of the WebLogic JDBC statement cache. Statement caching is normal behaviour (i.e. not a bug) but it can look a lot like a statement leak and can sometimes cause high levels of heap usage, so needs to be tuned appropriately.
Some non JDBC examples now...
select creationTime from weblogic.servlet.internal.session.MemorySessionData
This one looks at WebLogic sessions. In particular we're interested in any that have been hanging around for a long time.
SELECT toString(destination.name) FROM weblogic.jms.client.JMSProducer
This query was written to investigate a JMS connection leak. We used it to find some code that was not closing down its JMS API objects correctly.
Finally, a non-WebLogic and Oracle example...
SELECT toString(fDocumentURI), toString(docElement.name) FROM org.apache.xerces.dom.DeferredDocumentImpl
Many applications use XML, so this query looks at XML documents that are being retained in the heap.
I hope that this has given you a quick taste of OQL and that you will get some ideas for queries that will help you to solve other problems.
Friday, 29 July 2011
Wednesday, 18 May 2011
Monitoring Application Locks in Oracle
Oracle provides a variety of forms of locking protection for SQL operations to ensure that correct transactional semantics are provided to applications. Nine times out of ten when looking at issues related to locking, we will be interested in the locking facilities used by SQL, for example by monitoring row lock contention and tracking down which objects are the subject of the contention.
For some purposes, the locking provided by SQL operations does not meet the needs of the application. For these situations, Oracle provides the DBMS_LOCK package which provides application level locking.
This posting describes how to understand application level locking activity from AWR, ASH and other sources of information. It will help you to understand Oracle wait events like 'enq: UL - contention' and diagnose one possible cause of 'missing' response time in which some of the info provided by the Oracle AWR report may not be quite what you would expect.
Locking Strategies
There are two types of strategy that I've encountered when looking at application level locking. The first strategy uses DBMS_LOCK.REQUEST to try to acquire a lock and optionally specify the length of time for which the application is prepared to wait if another session already has the lock.
The second strategy is one that I would call 'polling' in which the application performs a rapid check to try to acquire a shared resource. This may use DBMS_LOCK with a very short timeout or it could (more likely) use a completely different implementation. If the resource cannot be acquired then the application waits using DBMS_LOCK.SLEEP for a period of time before retrying.
Trying it Out
I wanted to be able to run some predictable tests and then look at the results using various monotoring tools. For this purpose, I used some sample code that in the form of a PL/SQL package creates and then acquires an application lock called 'printer_lock' using DBMS_LOCK. I then started two sessions using SQL*Plus. In the first session, I created the lock and acquired it. In the second session I tried again to acquire the same lock which of course caused this session to wait because the lock was held by the other session.
I also added my own procedure to call DBMS_LOCK.SLEEP. In this case I didn't do any real 'locking' - I just wanted to see how a session calling this procedure would show up in the monitoring reports.
Visibility in Performance Reports
AWR can shed light on the wait time for application level locking using DBMS_LOCK.REQUEST. From this we can get a good understanding of whether our application might be getting delayed by application locks.
The first sections that contain information that we're interested are the 'wait class' and 'wait events'. Let's look at the more detailed 'wait events' section first. Here we will see the wait event 'enq: UL - contention' providing details of the total time waited while using APIs such as DBMS_LOCK.REQUEST (but not SLEEP) to acquire a lock. This info is also summarized into the wait class under 'Application'.

If the locking is being executed by PL/SQL code then AWR may also show us the top-level calling PL/SQL procedure in the 'SQL by Elapsed Time' section. The time spent waiting to acquire the lock will be counted in the elapsed time of this procedure.

The ASH report provides similar visibility, again highlighting the same wait event and the calling procedure. It can also provide details of the session that is waiting. Because ASH works by sampling it may give a slightly different picture from that shown by AWR and can be a better tool for some types of problem.


Because the meaning of any locks is application defined, neither AWR nor ASH provide any information regarding the resource that is the subject of any contention. We will look at how to diagnose this later.
For applications using a polling strategy, the visibility is not so good. In fact it would be very easy to miss it completely. The database performance reports seem to assume that time spent in DBMS_LOCK.SLEEP is of little of no interest to the audience of an AWR or ASH report. It is visible in the AWR report as the wait event 'PL/SQL lock timer', but you will need to look carefully to find this event because it appears very low down in the table (possibly right at the end), even if the time waited is very high.

The thing which is perhaps more surprising is that time spend in DBMS_LOCK.SLEEP is not counted in the elapsed time of the calling procedure. This means that for any procedure that sleeps in this way, you can't rely on the elapsed time reported by AWR. The same principle seems to apply to ASH - if the ASH sample catches the procedure sleeping like this then it doesn't seem to register it as a 'hit' on the calling procedure at all. This may make sense to someone looking at a problem from a database infrastructure perspective, but to an application developer looking at an AWR or ASH report it is very counter-intuitive.
System Tables and Views
As I said earlier, neither AWR nor ASH will shed much light on the resources that are the subject of application level locking conflicts. To get any detail on this we will need to query some system tables and views.
The first query looks for user locks. The most interesting columns are CTIME (which I think is the number of seconds since the lock was acquired), the SID which is the session currently holding the lock and ID1 which is used in the second query
SQL> select * from v$lock where TYPE = 'UL';
ADDR KADDR SID TY ID1 ID2 LMODE REQUEST -------- -------- ---------- -- ---------- ---------- ---------- ---------- CTIME BLOCK ---------- ---------- 1EF3E270 1EF3E29C 35 UL 1073741921 0 6 0 76 0
The second query looks up the lock name using the ID from the previous query. Clearly since we are dealing with application level locking, the meaning of the lock name is application-defined, so you will need to use your knowledge of the application to figure out what it means and whether you can do anything to improve the situation. Note that the 'expiration' column does not relate to the tenure of the lock by any session, but rather the lifetime of this particular application-level lock. It can be set when the lock is created by DBMS_LOCK.ALLOCATE_UNIQUE and defaults to 10 days.
SQL> select * from dbms_lock_allocated where lockid=1073741921;
NAME
--------------------------------------------------------------------------------
LOCKID EXPIRATIO
---------- ---------
printer_lock
1073741921 21-MAY-11
Naturally you could join the two queries, but I will leave that as an exercise for the reader.
Lock Housekeeping
The previous section mentioned the expiration time of an application level lock. In some circumstances this may also have a performance impact for your application. The reason is buried in the following sentence from the Oracle documentation…
"Subsequent calls to ALLOCATE_UNIQUE may delete expired locks to recover space."
The implication of this is that the housekeeping of the dbms_lock_allocated system table can also get mixed up with your application's execution. The system table is indexed only by name but the deletion statement used for housekeeping accesses the table by expiration date so the housekeeping query may cause a performance problem if your application creates a lot of locks with different names.
Here is an example AWR from an application that is being hit by this issue

For some purposes, the locking provided by SQL operations does not meet the needs of the application. For these situations, Oracle provides the DBMS_LOCK package which provides application level locking.
This posting describes how to understand application level locking activity from AWR, ASH and other sources of information. It will help you to understand Oracle wait events like 'enq: UL - contention' and diagnose one possible cause of 'missing' response time in which some of the info provided by the Oracle AWR report may not be quite what you would expect.
Locking Strategies
There are two types of strategy that I've encountered when looking at application level locking. The first strategy uses DBMS_LOCK.REQUEST to try to acquire a lock and optionally specify the length of time for which the application is prepared to wait if another session already has the lock.
The second strategy is one that I would call 'polling' in which the application performs a rapid check to try to acquire a shared resource. This may use DBMS_LOCK with a very short timeout or it could (more likely) use a completely different implementation. If the resource cannot be acquired then the application waits using DBMS_LOCK.SLEEP for a period of time before retrying.
Trying it Out
I wanted to be able to run some predictable tests and then look at the results using various monotoring tools. For this purpose, I used some sample code that in the form of a PL/SQL package creates and then acquires an application lock called 'printer_lock' using DBMS_LOCK. I then started two sessions using SQL*Plus. In the first session, I created the lock and acquired it. In the second session I tried again to acquire the same lock which of course caused this session to wait because the lock was held by the other session.
I also added my own procedure to call DBMS_LOCK.SLEEP. In this case I didn't do any real 'locking' - I just wanted to see how a session calling this procedure would show up in the monitoring reports.
Visibility in Performance Reports
AWR can shed light on the wait time for application level locking using DBMS_LOCK.REQUEST. From this we can get a good understanding of whether our application might be getting delayed by application locks.
The first sections that contain information that we're interested are the 'wait class' and 'wait events'. Let's look at the more detailed 'wait events' section first. Here we will see the wait event 'enq: UL - contention' providing details of the total time waited while using APIs such as DBMS_LOCK.REQUEST (but not SLEEP) to acquire a lock. This info is also summarized into the wait class under 'Application'.

If the locking is being executed by PL/SQL code then AWR may also show us the top-level calling PL/SQL procedure in the 'SQL by Elapsed Time' section. The time spent waiting to acquire the lock will be counted in the elapsed time of this procedure.

The ASH report provides similar visibility, again highlighting the same wait event and the calling procedure. It can also provide details of the session that is waiting. Because ASH works by sampling it may give a slightly different picture from that shown by AWR and can be a better tool for some types of problem.


Because the meaning of any locks is application defined, neither AWR nor ASH provide any information regarding the resource that is the subject of any contention. We will look at how to diagnose this later.
For applications using a polling strategy, the visibility is not so good. In fact it would be very easy to miss it completely. The database performance reports seem to assume that time spent in DBMS_LOCK.SLEEP is of little of no interest to the audience of an AWR or ASH report. It is visible in the AWR report as the wait event 'PL/SQL lock timer', but you will need to look carefully to find this event because it appears very low down in the table (possibly right at the end), even if the time waited is very high.

The thing which is perhaps more surprising is that time spend in DBMS_LOCK.SLEEP is not counted in the elapsed time of the calling procedure. This means that for any procedure that sleeps in this way, you can't rely on the elapsed time reported by AWR. The same principle seems to apply to ASH - if the ASH sample catches the procedure sleeping like this then it doesn't seem to register it as a 'hit' on the calling procedure at all. This may make sense to someone looking at a problem from a database infrastructure perspective, but to an application developer looking at an AWR or ASH report it is very counter-intuitive.
System Tables and Views
As I said earlier, neither AWR nor ASH will shed much light on the resources that are the subject of application level locking conflicts. To get any detail on this we will need to query some system tables and views.
The first query looks for user locks. The most interesting columns are CTIME (which I think is the number of seconds since the lock was acquired), the SID which is the session currently holding the lock and ID1 which is used in the second query
SQL> select * from v$lock where TYPE = 'UL';
ADDR KADDR SID TY ID1 ID2 LMODE REQUEST -------- -------- ---------- -- ---------- ---------- ---------- ---------- CTIME BLOCK ---------- ---------- 1EF3E270 1EF3E29C 35 UL 1073741921 0 6 0 76 0
The second query looks up the lock name using the ID from the previous query. Clearly since we are dealing with application level locking, the meaning of the lock name is application-defined, so you will need to use your knowledge of the application to figure out what it means and whether you can do anything to improve the situation. Note that the 'expiration' column does not relate to the tenure of the lock by any session, but rather the lifetime of this particular application-level lock. It can be set when the lock is created by DBMS_LOCK.ALLOCATE_UNIQUE and defaults to 10 days.
SQL> select * from dbms_lock_allocated where lockid=1073741921;
NAME
--------------------------------------------------------------------------------
LOCKID EXPIRATIO
---------- ---------
printer_lock
1073741921 21-MAY-11
Naturally you could join the two queries, but I will leave that as an exercise for the reader.
Lock Housekeeping
The previous section mentioned the expiration time of an application level lock. In some circumstances this may also have a performance impact for your application. The reason is buried in the following sentence from the Oracle documentation…
"Subsequent calls to ALLOCATE_UNIQUE may delete expired locks to recover space."
The implication of this is that the housekeeping of the dbms_lock_allocated system table can also get mixed up with your application's execution. The system table is indexed only by name but the deletion statement used for housekeeping accesses the table by expiration date so the housekeeping query may cause a performance problem if your application creates a lot of locks with different names.
Here is an example AWR from an application that is being hit by this issue

Thursday, 31 March 2011
Getting the Big Picture from AWR
Oracle AWR reports are one of the first tools that I turn to when I am asked to look at a database performance issue. They contain a huge amount of very useul information and can often lead me straight to the cause of the problem. But sometimes they don't - there are some situations where the data provided by a single AWR report just starts to feel like a whole bunch of meaningless numbers.
The reason for this is simple - some problems don't show up as obviously 'bad' things such as excessive elapsed time, I/O or CPU consumption. We only know what 'bad' looks like if we can also see what 'good' looks like.
Sometimes when I am in this situation the answer is quick and easy - I can identify another time period when performance was 'good', run an AWR and compare the two results. If I have the right Oracle version and sufficient access then I can even ask Enterprise Manager to do it for me.
But there are still some situations where this approach doesn't give a clear answer. Perhaps there are multiple types of workload running and we can't find an obvious time period to use as our 'good' baseline.
There is a third approach that I have used to good effect in these situations - run a set of AWR (and possibly ASH) reports for consecutive time periods (let's say one hour each) and get hold of thansaction throughput and response time stats from your application for the same time periods. Create a simple spreadsheet with the interesting stats - application throughput, response time, database CPU usage, wait events and perhaps some of the performance stats for any queries you suspect. You can then graph how these things vary over time. Looking at a graph like this often helps me to figure out the cause of the problem.
Let's look at an example. The Excel graph below was done to investigate a temporary drop in application throughput that didn't show a very obvious cause in a single AWR due to the level of other activity happening at the same time. Picking 6-7PM as a 'good' period and comparing the 5PM and 6PM AWR reports didn't give a clear answer either.

The graph plots (on the primary axis) the SQL elapsed time as a line and the database CPU and key wait times as a stacked area chart - these should almost add up to the elapsed time. On the secondary axis you can see an orange line showing the drop in throughput at 4PM and 5PM.
So how do we use this graph to find the root cause? - any wait events that are not causing the issue are likely to drop as application throughput drops. A wait event that is causing the issue will probably stay constant or increase. From this graph we can see that row lock contention is the likely cause. We can also see that row lock waits are still significant at other times, which is why comparing just two AWRs didn't give a clear answer in this case.
You can use some clever ways to get the data for the graphs such as querying the AWR views directly or writing a script to parse the AWR report and extract the info. These are fine and dandy if you are ready to do them before you are under pressure to solve the issue. I didn't do either - I just manually typed the info into Excel - it didn't take very long.
The reason for this is simple - some problems don't show up as obviously 'bad' things such as excessive elapsed time, I/O or CPU consumption. We only know what 'bad' looks like if we can also see what 'good' looks like.
Sometimes when I am in this situation the answer is quick and easy - I can identify another time period when performance was 'good', run an AWR and compare the two results. If I have the right Oracle version and sufficient access then I can even ask Enterprise Manager to do it for me.
But there are still some situations where this approach doesn't give a clear answer. Perhaps there are multiple types of workload running and we can't find an obvious time period to use as our 'good' baseline.
There is a third approach that I have used to good effect in these situations - run a set of AWR (and possibly ASH) reports for consecutive time periods (let's say one hour each) and get hold of thansaction throughput and response time stats from your application for the same time periods. Create a simple spreadsheet with the interesting stats - application throughput, response time, database CPU usage, wait events and perhaps some of the performance stats for any queries you suspect. You can then graph how these things vary over time. Looking at a graph like this often helps me to figure out the cause of the problem.
Let's look at an example. The Excel graph below was done to investigate a temporary drop in application throughput that didn't show a very obvious cause in a single AWR due to the level of other activity happening at the same time. Picking 6-7PM as a 'good' period and comparing the 5PM and 6PM AWR reports didn't give a clear answer either.

The graph plots (on the primary axis) the SQL elapsed time as a line and the database CPU and key wait times as a stacked area chart - these should almost add up to the elapsed time. On the secondary axis you can see an orange line showing the drop in throughput at 4PM and 5PM.
So how do we use this graph to find the root cause? - any wait events that are not causing the issue are likely to drop as application throughput drops. A wait event that is causing the issue will probably stay constant or increase. From this graph we can see that row lock contention is the likely cause. We can also see that row lock waits are still significant at other times, which is why comparing just two AWRs didn't give a clear answer in this case.
You can use some clever ways to get the data for the graphs such as querying the AWR views directly or writing a script to parse the AWR report and extract the info. These are fine and dandy if you are ready to do them before you are under pressure to solve the issue. I didn't do either - I just manually typed the info into Excel - it didn't take very long.
Monday, 28 February 2011
Outbound Load Balancing Considered Harmful
When designing clustered WebLogic deployments that use JMS it is usual to introduce load balancing into the JMS infrastructure so that incoming transaction arriving via JMS get distributed evenly across the servers in the cluster. The way that this is done in WebLogic is by creating a distributed destination with an individual physical queue in each member of the cluster. This allows the application components (e.g. EJB Message Driven Beans) to be configured with a single JNDI name so that the same application component can be deployed to every node in the cluster and will continue to work even if a cluster member goes down. Load balancing is enabled via the connection factory settings by specifying that the JMS connection factory should have load balancing enabled and (usually) server affinity disabled. This is usually a good thing.
For outbound messages (e.g. response messages from the same transactions) it is also normal to set up a distributed destination, again so that the application can be written with a single configured JNDI name which will work everywhere in the cluster. It is also possible to use a load balanced connection factory for the outbound messages. I can see no real advantages to using load balancing in this context. Gut feel and colleagues told me that it was a bad idea but until recently I could not point to any proven problems with this setup.
I have now seen an example of a real problem which seems to be happen when outbound load balancing is used…
First a little scene setting. One of the other advantages of clustering is that when we find ourselves facing one of those situations that should not happen and need to restart the application we can do so without making the whole system unavailable by doing a ‘rolling bounce’ in which the cluster members are bounced in turn so that there is never a time when none of them are available.
Recently we received reports of that one of our client systems was occasionally timing out waiting for JMS responses from us. This seemed to be happening in bursts at the same time as we were doing a rolling bounce to resolve an unrelated issue. Checking our database showed that we had processed the transaction and recorded a response message. Checking the logs, however, showed that there had been a problem…
[16/02/11 04:01:48:048 GMT] ABC_COMPONENT ERROR Exception Logger: Caught exception during processing void com.xyz.abc.common.servicelayer.SimpleJmsSender.sendMessage(String, Map)
org.springframework.jms.IllegalStateException: [JMSClientExceptions:055076]The session is closed; nested exception is weblogic.jms.common.AlreadyClosedException: [JMSClientExceptions:055076]The session is closed
at org.springframework.jms.support.JmsUtils.convertJmsAccessException(JmsUtils.java:252)
at org.springframework.jms.support.JmsAccessor.convertJmsAccessException(JmsAccessor.java:172)
Collecting up all of the logs from the cluster members showed that these exceptions always happened when one of the other managed servers in the cluster was being bounced. I concluded from this that the outbound messages were being round-robin load balanced across all of the managed servers and that when one server was bounced it caused errors to the applications running on the remaining servers.
Now I think that WebLogic JMS should handle this rather better. I also know that the application’s error handling needs to be improved so that it doesn’t commit the database changes if the JMS response message transmission fails. Nevertheless it does highlight a scenario in which outbound load balancing introduces the possibility of a problem which would not be there if the outbound messages were sent without load balancing.
Conclusion: when using a distributed JMS destination to send outbound messages from a cluster you should use a connection factory with load balancing disabled and server affinity enabled.
Before closing it’s worth observing that outbound load balancing is something that I’ve seen configured on several WebLogic projects and thinking about why this is so…
Most of the projects that I’ve seen have begun life in a non-clustered setup. In such a setup it is usual to use a single JMS connection factory for both inbound and outbound messages. Unless there is some special tuning required then there is no real problem with such a setup. When clustering is introduced the team reads the manual, learns about distributed JMS destinations and creates them. They introduce inbound load balancing by reconfiguring their existing connection factory but stick with the single connection factory setup and overlook the fact that they have also implicitly introduced outbound load balancing.
For outbound messages (e.g. response messages from the same transactions) it is also normal to set up a distributed destination, again so that the application can be written with a single configured JNDI name which will work everywhere in the cluster. It is also possible to use a load balanced connection factory for the outbound messages. I can see no real advantages to using load balancing in this context. Gut feel and colleagues told me that it was a bad idea but until recently I could not point to any proven problems with this setup.
I have now seen an example of a real problem which seems to be happen when outbound load balancing is used…
First a little scene setting. One of the other advantages of clustering is that when we find ourselves facing one of those situations that should not happen and need to restart the application we can do so without making the whole system unavailable by doing a ‘rolling bounce’ in which the cluster members are bounced in turn so that there is never a time when none of them are available.
Recently we received reports of that one of our client systems was occasionally timing out waiting for JMS responses from us. This seemed to be happening in bursts at the same time as we were doing a rolling bounce to resolve an unrelated issue. Checking our database showed that we had processed the transaction and recorded a response message. Checking the logs, however, showed that there had been a problem…
[16/02/11 04:01:48:048 GMT] ABC_COMPONENT ERROR Exception Logger: Caught exception during processing void com.xyz.abc.common.servicelayer.SimpleJmsSender.sendMessage(String, Map)
org.springframework.jms.IllegalStateException: [JMSClientExceptions:055076]The session is closed; nested exception is weblogic.jms.common.AlreadyClosedException: [JMSClientExceptions:055076]The session is closed
at org.springframework.jms.support.JmsUtils.convertJmsAccessException(JmsUtils.java:252)
at org.springframework.jms.support.JmsAccessor.convertJmsAccessException(JmsAccessor.java:172)
Collecting up all of the logs from the cluster members showed that these exceptions always happened when one of the other managed servers in the cluster was being bounced. I concluded from this that the outbound messages were being round-robin load balanced across all of the managed servers and that when one server was bounced it caused errors to the applications running on the remaining servers.
Now I think that WebLogic JMS should handle this rather better. I also know that the application’s error handling needs to be improved so that it doesn’t commit the database changes if the JMS response message transmission fails. Nevertheless it does highlight a scenario in which outbound load balancing introduces the possibility of a problem which would not be there if the outbound messages were sent without load balancing.
Conclusion: when using a distributed JMS destination to send outbound messages from a cluster you should use a connection factory with load balancing disabled and server affinity enabled.
Before closing it’s worth observing that outbound load balancing is something that I’ve seen configured on several WebLogic projects and thinking about why this is so…
Most of the projects that I’ve seen have begun life in a non-clustered setup. In such a setup it is usual to use a single JMS connection factory for both inbound and outbound messages. Unless there is some special tuning required then there is no real problem with such a setup. When clustering is introduced the team reads the manual, learns about distributed JMS destinations and creates them. They introduce inbound load balancing by reconfiguring their existing connection factory but stick with the single connection factory setup and overlook the fact that they have also implicitly introduced outbound load balancing.
Monday, 31 January 2011
Dashboards for Production Monitoring
We've been using CA Wily Introscope to monitor one of our production systems for several years. Some dashboards had been developed when the tool was first installed and these have been in use ever since. These dashboards provided useful information, but had been built from a technical perspective and didn't really reflect the way that we usually think about our system. For example, the top level dashboard showed items like 'JMS Subsystem' and 'Java Heap'. When one of these indicated an issue, it wasn't really very clear which service was being impacted… and in some cases whether there was really a problem at all.
Following the experience with Wily for performance test monitoring (see last month's posting) I decided to spend some time creating some new dashboards that were a better match for the way we think about our system - i.e. as a collection of services each one of which might be working well or having some problems. I therefore wanted a top-level dashboard with one traffic light indicator for each of our key services and drill-down into a more detailed dashboard for each individual service to allow problems to be tracked down. I will return to this later.
This posting describes what I wanted to do, what I did and what I learned in the process. It's mostly about Wily but other tools are available so I hope (dear reader) that the principles described would apply reasonably well to a different tool.
Individual Service Dashboards
To figure out whether an individual service is working properly we need to monitor several things…
Our application is clustered, so in most cases I needed to create a Metric Group to bring together the numbers for a particular metric from each member of the cluster. For most of these I then created an Alert to contain the threshold values that would trigger an amber or red warning.
Sometimes I was able to find a Service Level Agreement (SLA) to set the alert thresholds. In cases where there was no SLA I used the Wily Investigator to get a picture of the average and maximum values for the metric over the past month and set thresholds based on this.
For some metrics (e.g. throughput) it was not appropriate to create an Alert. For the error alerts on our user interface I needed to ask Wily to count how many occurrences happened in a given period of time (e.g. 5 minutes) because in many cases a small error rate is quite normal and acceptable.
The service dashboards typically contain a graph to track the values of each metric across all managed servers plus a traffic light showing the status of the alert. In most cases I found it best to bind the graph to the alert rather than the metric group so that I got an amber and a red line on the graph to show the trigger points for each alert like the example below.

Laying out the dashboards was challenging in some cases and for some more complex services I needed to resort to multiple layers of drill-down to show all of the graphs that were needed. In some cases I did this by having a higher level dashboard with 'throughput', 'response time' and 'queue backlog' panels and providing drill-down to more detailed dashboards from here. For other services it was more appropriate to break the service down into functional elements (sub-services) and provide a second level drill-down dashboard for each of these. Here's an example.

Top Level Dashboards
Wily allows us to combine individual alerts into higher level summary alerts - in multiple tiers if necessary. This is exactly what I did to create the top level dashboard and also for the summary dashboard where I broke things down into sub-services. The top level dashboard with one traffic light per service is shown below. I also added a CPU usage graph below the traffic lights for information (and because there was some free space).

Tricky Things
So far so good, but not everything went totally as I wanted…
As I said at the beginning, my dashboard is focused on monitoring the services supported by our application. As a result, the dashboards focus on the 'front end' metrics. Wily also provides a lot of visibility of the 'back end' (e.g. JDBC calls into Oracle) and infrastructure (e.g. Java garbage collector behaviour) but none of these are used by my dashboards. I figured that if there is a backend issue then it must have a visible effect on the front end service otherwise it isn't really an issue at all. I would therefore expect the dashboard to detect a problem and flag it as an amber or red condition. It would, of course, be nice to be able to drill down and isolate this problem to the database (or whatever), but I've left that as a possible improvement for the future.
Following the experience with Wily for performance test monitoring (see last month's posting) I decided to spend some time creating some new dashboards that were a better match for the way we think about our system - i.e. as a collection of services each one of which might be working well or having some problems. I therefore wanted a top-level dashboard with one traffic light indicator for each of our key services and drill-down into a more detailed dashboard for each individual service to allow problems to be tracked down. I will return to this later.
This posting describes what I wanted to do, what I did and what I learned in the process. It's mostly about Wily but other tools are available so I hope (dear reader) that the principles described would apply reasonably well to a different tool.
Individual Service Dashboards
To figure out whether an individual service is working properly we need to monitor several things…
- What is the response time of the service and is it within acceptable limits?
- What is the throughput for the service?
- For a JMS messaging service, how many messages are sat in the queue?
- For a JMS service, does the queue have one or more listeners connected?
- Are there any messages in the error queue?
- Is the application reporting an abnormal number of errors?
Our application is clustered, so in most cases I needed to create a Metric Group to bring together the numbers for a particular metric from each member of the cluster. For most of these I then created an Alert to contain the threshold values that would trigger an amber or red warning.
Sometimes I was able to find a Service Level Agreement (SLA) to set the alert thresholds. In cases where there was no SLA I used the Wily Investigator to get a picture of the average and maximum values for the metric over the past month and set thresholds based on this.
For some metrics (e.g. throughput) it was not appropriate to create an Alert. For the error alerts on our user interface I needed to ask Wily to count how many occurrences happened in a given period of time (e.g. 5 minutes) because in many cases a small error rate is quite normal and acceptable.
The service dashboards typically contain a graph to track the values of each metric across all managed servers plus a traffic light showing the status of the alert. In most cases I found it best to bind the graph to the alert rather than the metric group so that I got an amber and a red line on the graph to show the trigger points for each alert like the example below.

Laying out the dashboards was challenging in some cases and for some more complex services I needed to resort to multiple layers of drill-down to show all of the graphs that were needed. In some cases I did this by having a higher level dashboard with 'throughput', 'response time' and 'queue backlog' panels and providing drill-down to more detailed dashboards from here. For other services it was more appropriate to break the service down into functional elements (sub-services) and provide a second level drill-down dashboard for each of these. Here's an example.

Top Level Dashboards
Wily allows us to combine individual alerts into higher level summary alerts - in multiple tiers if necessary. This is exactly what I did to create the top level dashboard and also for the summary dashboard where I broke things down into sub-services. The top level dashboard with one traffic light per service is shown below. I also added a CPU usage graph below the traffic lights for information (and because there was some free space).

Tricky Things
So far so good, but not everything went totally as I wanted…
- I couldn't find a way to combine metrics using any kind of logic - for example if I wanted to raise an alert if a queue had zero listeners AND had a non-zero message count.
- I have not so far found any way to turn cumulative metrics (e.g. events since startup) into a number of events per interval. This would be very useful for some JMX metrics that are only available as a cumulative number.
- For WebLogic JMS queues it is really necessary to know both the 'current' message count and the 'pending' (i.e. being processed or buffered for delivery) count and to sum these together. It is possible to do this using Wily calculators but this gets complicated in a cluster because we really need a separate calculator per metric per cluster member… which is pretty time-consuming to set up. In practice I have ignored the pending count in most cases - except for those parts of the application where it is really critical.
- Debugging summary alerts can be a bit tricky - I found one that kept going amber or red on the top level dashboard but after drilling down into the detailed dashboard everything was green. In the end I traced it to a duplicate alert that was misconfigured and not shown on the dashboard but it took a lot of manual checking to track this down.
- Wily can't 'see' everything. This isn't really a tool issue, but it does mean that 'green' on the Wily dashboard doesn't necessarily mean that everything is fine. For example, some parts of our application keep internal 'transaction queues' in application database tables and other parts use background jobs in the database which may go wrong in interesting ways without Wily having any visibility. The Wily Oracle Agent might help here, but at the moment we don't have it installed.
As I said at the beginning, my dashboard is focused on monitoring the services supported by our application. As a result, the dashboards focus on the 'front end' metrics. Wily also provides a lot of visibility of the 'back end' (e.g. JDBC calls into Oracle) and infrastructure (e.g. Java garbage collector behaviour) but none of these are used by my dashboards. I figured that if there is a backend issue then it must have a visible effect on the front end service otherwise it isn't really an issue at all. I would therefore expect the dashboard to detect a problem and flag it as an amber or red condition. It would, of course, be nice to be able to drill down and isolate this problem to the database (or whatever), but I've left that as a possible improvement for the future.
Friday, 24 December 2010
JRockit Mission Control vs Wily - Postscript
We've just completed our project to performance test an Apache Camel integration solution hosted on WebLogic. I thought it would be useful to write a few words about our experiences using JRMC and Wily to monitor the tests as a postscript to 'JRockit Mission Control vs Wily'
CA Wily Introscope
We wound up using Wily for most of our monitoring needs in the WebLogic tier. On the whole it did the job that we expected of it very well.
Our main thoughts on our Wily experience are...
JRockit Mission Control
We had a couple of issues with JRMC right from the start. These were probably not faults with the tool, but they severely limited its usefulness
We were able to use JRMC to fill this gap by using JRMC method profiling to trap the web service and TIBCO callouts. This wasn't a perfect setup because it could only give us an average response time for the whole test. It also had a few other issues:-
Summary
On the whole, our experience has reinforced my original conclusions that JRMC is a good tool for single developers or testers to quickly get a handle on how their Java code is performing but that Wily is much stronger in a team environment or for production monitoring.
In the end it wasn't an 'either/or' decision for us - we needed to use both tools to capture the data that we needed.
CA Wily Introscope
We wound up using Wily for most of our monitoring needs in the WebLogic tier. On the whole it did the job that we expected of it very well.
Our main thoughts on our Wily experience are...
- The fact that Wily's monitoring is 'always on' was a big advantage, as well as the ability to get historical results in graphical or CSV format.
- We were not able to use any custom probes because Wily was installed and configured by the customer's infrastructure team and getting custom probes created, tested and deployed was just going to need too many phone calls and email round trips.
- Initially there were quite a lot of navigation steps and other clicking around needed to capture all of the metrics that we needed into graphs or CSV form. We largely overcame this by creating some metric groupings and custom dashboards to bring all of the necessary data together into one place.
- For some reason, the JMX data from the Camel route MBeans was not captured by Wily during our tests (although the processor MBeans worked fine and the route MBeans worked fine before we started the tests).
- Wily didn't recognise our Apache CXFServlet as a 'Frontend' (but it knew it was a Servlet) nor did it recognise outbound web service and TIBCO calls as 'Backends', so some of the more advanced features (e.g. transaction tracing) were not usable.
- Wily often picks a non-intuitive sampling interval for graphs (e.g. 6 minutes) but it was quite easy to override this and use something more sensible.
- Data captured from JMX MBeans needed some further analysis afterwards to calculate the throughput and average response times during the test period. It may have been possible to use Wily calculators to automate this, but we didn't have time to get that far
JRockit Mission Control
We had a couple of issues with JRMC right from the start. These were probably not faults with the tool, but they severely limited its usefulness
- Our customer had an older version of JRockit than that supported by the latest version of JRMC, so we needed to downgrade to JRMC 3.1.2 before most of the JRMC features would work.
- We never managed to get any kind of recording capability to work. JRMC 3.1.2 has JRA recording, but whenever we tried this it would cause the WebLogic managed server to go into an 'UNKNOWN' state and stop working. I've tested JRA recording on my local setup and it works fine, so this issue seems to be specific to our customer's managed WebLogic setup. It may have been fixable but we didn't get this far.
We were able to use JRMC to fill this gap by using JRMC method profiling to trap the web service and TIBCO callouts. This wasn't a perfect setup because it could only give us an average response time for the whole test. It also had a few other issues:-
- Someone needs to remember to start the method profiler before the test and save the results afterwards.
- It isn't easy to share JRMC method profiling configurations (or any other JRMC configuration) with other team members, so each person had to set the probes up manually.
- Only one person can use method profiling on a managed server at a time. If someone accidentally starts profiling while another session is in progress the first session is terminated.
- We had one occasion on which the Windows machine running JRMC automatically rebooted itself part way through a 24 hour test run so we lost all of the JRMC data prior to the reboot.
Summary
On the whole, our experience has reinforced my original conclusions that JRMC is a good tool for single developers or testers to quickly get a handle on how their Java code is performing but that Wily is much stronger in a team environment or for production monitoring.
In the end it wasn't an 'either/or' decision for us - we needed to use both tools to capture the data that we needed.
Wednesday, 17 November 2010
How Fast is my Camel?
I'm working on a project using Apache Camel to do some web service and messaging bus transformation and integration. My part of the project is mainly concerned with performance testing, so I needed to figure out how we could measure the performance of various components within our Camel setup - both in terms of how our integration piece was performing and also how the various services on which we depend were performing.
For those not familiar with Camel you can find an overview here
To figure out how to make these measurements I set up a couple of sample contexts and routes and deployed them into a WebLogic 10.3 server. For no particularly good reason, both provide a service based on the Spring Web Services echo sample.
One route is based on the Camel CXF sample and uses a CXF endpoint, a custom transformation bean and a custom backend bean to generate the response.

The second route uses the Camel HTTP components to provide a servlet and then proxy the SOAP call to the same app running on another (Jetty) app server.

What we need to measure is:-
JMX
I was pleasantly surprised to find a bunch of Camel related JMX MBeans appear in the JRMC console without any need for me to make any changes to the application. Camel enables JMX by default and it seems that it also creates some usable default MBeans for each component.

Browsing through these it seems that most of them relate to the configuration of the Camel components rather than their runtime behaviour. Some of these include options to turn tracing on or off and reconfigure the detail level - useful but not quite what we are looking for. The two relevant parts of the tree for performance measurement are 'routes' and 'processors' because both of these contain invocation counts and timings. As their name suggests, 'routes' relates to the behaviour of the entire route and 'processors' to the behaviour of some individual components. The 'processors' tree doesnt cover every component - things like servlets that receive messages via HTTP and initiate the route processing are not available here, but their response time will in most cases equate to the response time of the whole route.
Below is a screenshot of one of the components in my proxying route showing the attributes that will alow us to monitor the number of invocations and response time. You can see the two custom MBeans in the echo_context route and the HTTP client in the servlet_echo_context route. Unfortunately the names of the MBeans don't seem to be very meaningful, but by browsing into the attributes it is usually possible to figure out which one is which. The attributes provided by the route level MBean are very similar.

We can therefore use JMX to monitor the performance of our Camel routes and individual components.
If you press the 'Visualize' button, you can also chart the value of one or more MBean attributes to see how they change over time. The chart will appear on the 'General' view in the console, soomething like the one below...

(Incidentally, if you want to graph behaviour over time and be able to zoom in and out etc then I think that Wily Introscope does a much better job - see my post comparing JRMC and Wily)
I noticed one bit of strangeness - the HTTP client MBean seems to report double the number of invocations that I would expect - each time the route runs the HTTP client's 'ExchangesTotal' count goes up by two.
Profiling Traps
The JMX MBeans will probably serve most of our day to day needs, but sometimes I expect we will want to 'drill down' a bit further to investigate performance issues. For this purpose, we can place traps or probes into the code which can make measurements at a level of detail lower than those provided by JMX.
These traps can be inserted using Aspect Oriented Programming technologies such as aspectj, Spring's built in AOP capabilities or using a monitoring tool such as Wily or JRMC.
If you want to use this approach, you need to have some knowledge of the code of the framework that you are using. You can get this by browsing the Javadocs or the source code itself or by running your app in a debugger, placing breakpoints at 'interesting' places and examining the call stack. Setting up a debugger takes some time, but I think it provides the answers that I want more quickly than trying to figure things out from the documentation or the source.
Here are some methods where I've placed traps to try out this technique...
Creating profiling traps in JRMC is fairly simple - go to the 'Advanced' view in the console and click the 'Add...' button under 'select methods to profile. JRMC will ask you for the class name. Assuming that the class is found, it will then allow you to select the methods that you want to profile.
Once the methods are selected, you need to click the 'Start Profiling' button (green triangle) to start capturing data. You should see something like the screenshot below.

Profiling traps can be used to get a more detailed picture of where response time is being sent. They are more complex to set up than JMX and probably incur some measurement overhead. They do have one other big drawback - they are based only on class and method, so you won't be able to separate out the stats for different component instances if you have a number of routes using the same type of component. For all of these reasons, method profiling is probably best restricted to very targeted tests in which you can focus your workload and your profiling traps purely on a small area of interest.
For those not familiar with Camel you can find an overview here
To figure out how to make these measurements I set up a couple of sample contexts and routes and deployed them into a WebLogic 10.3 server. For no particularly good reason, both provide a service based on the Spring Web Services echo sample.
One route is based on the Camel CXF sample and uses a CXF endpoint, a custom transformation bean and a custom backend bean to generate the response.

The second route uses the Camel HTTP components to provide a servlet and then proxy the SOAP call to the same app running on another (Jetty) app server.

What we need to measure is:-
- how many times is each component/route called in a given time period?
- how long does each route take to respond back to the client?
- where is the response time being spent? - in our own components or in calls to other systems?
JMX
I was pleasantly surprised to find a bunch of Camel related JMX MBeans appear in the JRMC console without any need for me to make any changes to the application. Camel enables JMX by default and it seems that it also creates some usable default MBeans for each component.

Browsing through these it seems that most of them relate to the configuration of the Camel components rather than their runtime behaviour. Some of these include options to turn tracing on or off and reconfigure the detail level - useful but not quite what we are looking for. The two relevant parts of the tree for performance measurement are 'routes' and 'processors' because both of these contain invocation counts and timings. As their name suggests, 'routes' relates to the behaviour of the entire route and 'processors' to the behaviour of some individual components. The 'processors' tree doesnt cover every component - things like servlets that receive messages via HTTP and initiate the route processing are not available here, but their response time will in most cases equate to the response time of the whole route.
Below is a screenshot of one of the components in my proxying route showing the attributes that will alow us to monitor the number of invocations and response time. You can see the two custom MBeans in the echo_context route and the HTTP client in the servlet_echo_context route. Unfortunately the names of the MBeans don't seem to be very meaningful, but by browsing into the attributes it is usually possible to figure out which one is which. The attributes provided by the route level MBean are very similar.

We can therefore use JMX to monitor the performance of our Camel routes and individual components.
If you press the 'Visualize' button, you can also chart the value of one or more MBean attributes to see how they change over time. The chart will appear on the 'General' view in the console, soomething like the one below...

(Incidentally, if you want to graph behaviour over time and be able to zoom in and out etc then I think that Wily Introscope does a much better job - see my post comparing JRMC and Wily)
I noticed one bit of strangeness - the HTTP client MBean seems to report double the number of invocations that I would expect - each time the route runs the HTTP client's 'ExchangesTotal' count goes up by two.
Profiling Traps
The JMX MBeans will probably serve most of our day to day needs, but sometimes I expect we will want to 'drill down' a bit further to investigate performance issues. For this purpose, we can place traps or probes into the code which can make measurements at a level of detail lower than those provided by JMX.
These traps can be inserted using Aspect Oriented Programming technologies such as aspectj, Spring's built in AOP capabilities or using a monitoring tool such as Wily or JRMC.
If you want to use this approach, you need to have some knowledge of the code of the framework that you are using. You can get this by browsing the Javadocs or the source code itself or by running your app in a debugger, placing breakpoints at 'interesting' places and examining the call stack. Setting up a debugger takes some time, but I think it provides the answers that I want more quickly than trying to figure things out from the documentation or the source.
Here are some methods where I've placed traps to try out this technique...
- org.apache.cxf.transport.servlet.AbstractHTTPServlet.handleRequest(HttpServletRequest, HttpServletResponse) - The entry point into my CXF driven route
- org.apache.camel.component.http.CamelServlet.service(HttpServletRequest, HttpServletResponse) - The entry point into my HTTP servlet driven route
- org.apache.camel.component.http.HttpProducer.executeMethod(HttpMethod) - The point where my HTTP servlet driven proxying route calls out to an external server
- my own custom bean methods
Creating profiling traps in JRMC is fairly simple - go to the 'Advanced' view in the console and click the 'Add...' button under 'select methods to profile. JRMC will ask you for the class name. Assuming that the class is found, it will then allow you to select the methods that you want to profile.
Once the methods are selected, you need to click the 'Start Profiling' button (green triangle) to start capturing data. You should see something like the screenshot below.
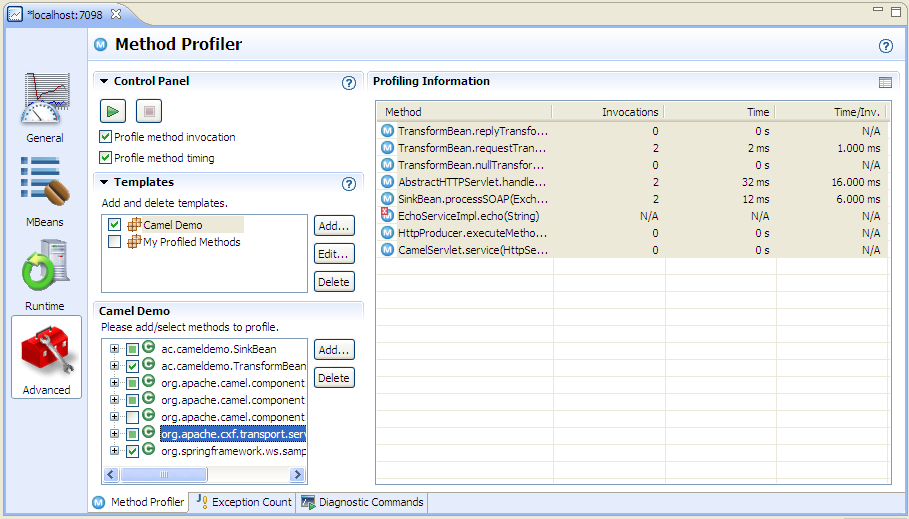
Profiling traps can be used to get a more detailed picture of where response time is being sent. They are more complex to set up than JMX and probably incur some measurement overhead. They do have one other big drawback - they are based only on class and method, so you won't be able to separate out the stats for different component instances if you have a number of routes using the same type of component. For all of these reasons, method profiling is probably best restricted to very targeted tests in which you can focus your workload and your profiling traps purely on a small area of interest.
Subscribe to:
Posts (Atom)

